[Einfluss der Pegelsteuerung bei adaptiver Bestimmung der Sprachverständlichkeitsschwelle im Störgeräusch sowie der Maskierung des kontralateralen Ohres in der Sprachaudiometrie bei normalhörenden Proband*innen und Cochlea-Implantat-Tragenden]
Moritz Gröschel 1Pia Stoppe 2
Heidi Olze 1
Tim Jürgens 2
1 Department of Otolaryngology, Charité – University Medicine Berlin, Germany
2 Institute of Acoustics, Department of Applied Natural Sciences, Technische Hochschule Lübeck, Germany
Zusammenfassung
Die Überprüfung der Sprachverständlichkeit im Störgeräusch ist ein essenzieller Bestandteil der Erfolgskontrolle und Qualitätssicherung bei Hörsystemen wie Cochlea-Implantaten (CI). Dabei kommen sowohl Verfahren mit festem Störgeräuschpegel (fixed-noise) als auch solche mit festem Sprachpegel (fixed-speech) zum Einsatz. Bei vielen CI-Tragenden mit relevantem Restgehör auf der Gegenseite ist zur validen Beurteilung des neu implantierten Ohrs eine Ausschaltung des kontralateralen Ohres erforderlich. Auch in der audiologischen Diagnostik ist dies häufig notwendig. Die vorliegende Studie vergleicht die adaptiv gemessenen Sprachverständlichkeitsschwellen (SRT) mittels OLSA im Störschall mit fixed-noise- und fixed-speech-Verfahren sowohl bei CI-Nutzenden als auch bei normalhörenden (NH) Probandinnen und Probanden. Zudem wurden die Sprachverständlichkeit und SRTs unter Okklusion beziehungsweise Maskierung des kontralateralen Ohres erhoben sowie die subjektive Präferenz der Testbedingungen erfasst. Die Ergebnisse zeigen keine signifikanten Unterschiede zwischen fixed-speech und fixed-noise in Bezug auf die SRTs in beiden Untersuchungsgruppen. Es zeigten sich keine signifikanten Differenzen zwischen Okklusion und Maskierung hinsichtlich der gemessenen Sprachverständlichkeit in CI-Nutzenden, trotz der Schallabschwächungsbegrenzung von Okklusion in der Praxis, wohingegen Maskierung in der NH-Gruppe signifikant niedrigere SRTs erzeugte im Vergleich zu Okklusion. CI-Nutzende äußerten eine Präferenz für das fixed-noise-Verfahren, während NH-Probandinnen und Probanden eine Präferenz für das fixed-speech-Verfahren angegeben haben. Beide Gruppen bevorzugten jedoch deutlich die Okklusion (Ohrstöpsel plus Kapselgehörschutz) gegenüber der Maskierung durch Rauschen zur Ausschaltung des kontralateralen Ohres. Die Ergebnisse sprechen für die Anwendung des fixed-noise-Verfahrens und eine Bevorzugung der Okklusion im klinischen Kontext bei CI-Nutzenden.
Schlüsselwörter
Sprachverständlichkeitsschwelle, konstante Sprache, konstantes Rauschen, kontralaterale Maskierung
Introduction
Testing speech intelligibility in noise has become indispensable for outcome assessment and quality control of hearing devices such as cochlear implants (CI). Sentence tests hereby are most representative for the speech intelligibility tasks that patients face in everyday life; thus, they are widely used in clinics [1], [2]. While there exist many different tests with everyday speech in different languages, the family of matrix sentence tests [3] has the advantage of an easy sentence structure with five words in a fixed syntactical order and low predictability, due to random choice of ten response alternatives per word. The adaptive procedure to vary the signal-to-noise ratio (SNR) based on patient’s responses aiming at a word recognition rate of 50% makes it an efficient way to determine the individual speech reception threshold (SRT).
The German version, the Oldenburg sentence test (OLSA) [4], is widely used in German-speaking countries for perceptive evaluation of hearing devices [5], such as CIs [6]. The recommended procedure of SRT-measurement with matrix tests, such as the OLSA, is to fix the noise level during a measurement run (e.g., at 65 dB SPL) and adaptively vary the speech level. This fixed-noise procedure is also used for other speech-in-noise tests in clinics, such as the hearing-in-noise test [7]. The fixed-noise procedure has the advantage of representing a non-changing background acoustic scene, which is more realistic for everyday life than ongoing changes in the background, as a fixed-speech procedure would have. However, also fixed-speech procedures have been used often [8], [9], [10], [11]. The main advantage of a fixed-speech procedure is first to ensure the same audibility of speech amplitudes within the mixed signal across the entire adaptive run and second the limitation of the sum level of speech and noise if the SRT-measurement drifts to high SNRs [12].
Wagener and Brand [13] found no significant difference in SRTs between fixed-speech and fixed-noise procedure in NH listeners for the OLSA using headphone-presentation. Dziemba and colleagues [12] extended these findings also towards CI users, but using loudspeaker presentation. They found no significant difference in SRTs measured using the fixed-speech or the fixed-noise procedure for those patients, who achieved an SRT better (i.e., lower) than +5 dB SNR. Larger differences between fixed-noise and fixed-speech procedure occurred, however, for CI users with poorer SRTs, which was related to the finding of Hey and colleagues [6] that SRT values beyond +5 dB SNR are less reliable due to poorer test-retest reliability.
While these studies for themselves found no significant difference across procedures, there has not yet been a study comparing fixed-noise and fixed-speech procedures with CI users and NH listeners in the exact same measurement setup. In addition, these studies did not investigate subjective preference ratings of patients comparing fixed-speech or fixed-noise procedure. However, such ratings would be desirable to recommend one procedure in clinical routine.
Expansion of CI candidacy in the last 15 years in the US [7] and in Germany [14] as two of the largest CI markets has allowed persons with contralateral acoustic hearing and even single-sided deaf patients (comprising one NH ear) to receive a CI. In addition, bilateral cochlear implantation is in many countries indicated if both ears meet indication criteria separately. In Germany, these candidacy criteria are guided by the “Weißbuch Cochlea-Implantat Versorgung” [15]. With the advent of many patients with substantial hearing contralaterally, monitoring the success of a newly implanted CI via speech-in-noise testing requires excluding the contralateral ear. Also, in audiological diagnostics exclusion of the contralateral ear is often necessary [16].
For bilateral CI patients without any residual acoustic hearing in either ear, the most used way to exclude the opposite ear is to simply switch off the contralateral speech processor [1], [17], [18], [19]. While the solution of switching off the contralateral hearing aid is also often used in bimodal CI users [1], [20], [21] this procedure bears the risk that some rests of acoustic hearing contaminate the CI speech test result.
Another solution is to stimulate the CI alone via direct audio input either via cable [10], [22], [23], [24], [25], via streaming, or by putting an over-ear headphone on top of the CI speech processor [24], [26], [27]. While these solutions effectively exclude the opposite ear, they also remove any head orientation related effects that may be important for speech intelligibility in spatial acoustic scenes [28]. An approach to retain head orientation-related effects, which is applicable in free-field loudspeaker speech testing, is to block the contralateral ear canal with ear plugs or ear muffs [2], [12], [25], [29] or present it with masking noise using insert ear phones [2], [18], [30]. To the authors’ knowledge, however, systematic investigations of the effect of contralateral occlusion or masking on speech intelligibility scores or SRTs for the implanted ear have not yet been done. In addition, also with occlusion and masking, preference ratings of patients are missing. Given that exclusion of one ear may substantially increase subjective listening effort [31], such ratings are important for choosing the best clinical method for patients with any contralateral acoustic hearing tested in free field.
The goals of the present study are therefore: First, to compare fixed-level and fixed-speech adaptive SRT-testing with the OLSA both in CI users and NH listeners within the exact same measurement setup; second, to compare speech intelligibility scores and SRTs (OLSA) in both listener groups for both occlusion and masking of the contralateral ear; and third, to investigate subjective pleasantness and preference of either of those methods.
Concerning the third goal, two concurring research hypotheses are considered reasonable: The “symmetric loudness perception hypothesis” states that the masking condition may lead to a more pleasurable experience for participants, and is therefore favored, because loudness perception in both ears is similar due to similar sound levels of the speech signal and the contralateral noise signal. In contrast, the “distraction hypothesis” states that masking with noise may be perceived as more distracting from the target signal presented on the opposite ear in comparison to the quiet present in the occlusion condition. This distraction may be perceived as less pleasurable and therefore less favorable. The statistical null hypotheses for all three goals were no differences across conditions tested.
Methods
Participants
The study included two experimental groups, 15 NH listeners and 26 CI users.
Inclusion criteria for the NH group was bilateral normal hearing with a pure-tone average (PTA4) threshold of ≤20 dB hearing level (HL) and a speech intelligibility score of ≥80% in the Freiburg Monosyllabic Word Test at 50 dB sound pressure level (SPL). The average age of the NH listeners was 39 years (range: 21–63 years), including 8 females and 7 males. All audiometric measurements were conducted using an Auritec AT 900 audiometer. Pure-tone thresholds were assessed via Beyerdynamic DT 48 headphones.
The demographic data of CI users is shown in Table 1 [Tab. 1]. CI user’s average age was 60 years (range: 21–86 years), with 10 females and 16 males. The average CI experience was 4 years (range: 0.5–28 years). Of these participants, 24 had postlingual and 2 had prelingual deafness. Six participants were bilaterally implanted (without any residual acoustic hearing) and 20 were unilaterally implanted, five of whom had a complete hearing loss (deafness) in the contralateral ear, whereas the remaining 15 unilateral CI users showed normal hearing in the contralateral ear (PTA4 threshold of ≤20 dB HL). Fifteen participants used devices from Cochlear, and eleven used implants from MED-EL. Participants submitted an informed consent prior attending the study.
Table 1: Demographic information on CI participants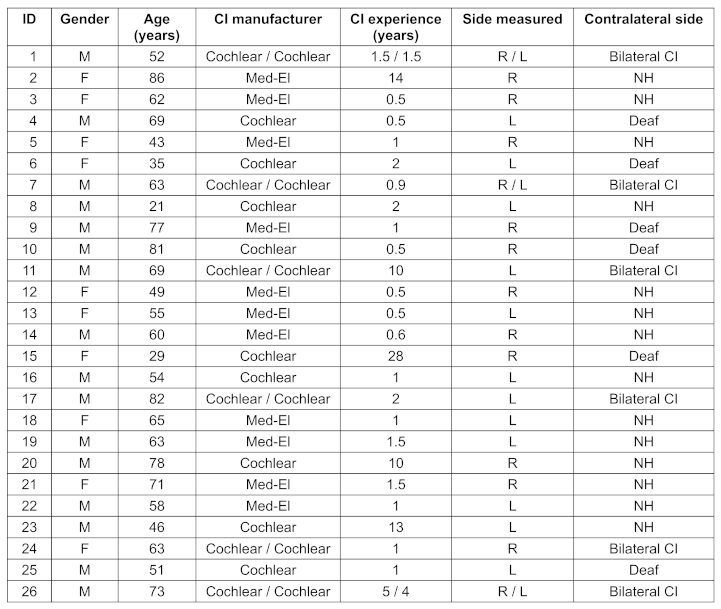
Audiometric testing
For NH listeners, speech intelligibility was assessed using the Freiburg Monosyllabic Word Test presented at 50 dB SPL in free-field conditions with an Auritec loudspeaker (maximum level of 90 dB SPL) positioned at 0°. For CI users, the same test was conducted at 65 dB SPL under identical free-field conditions [32]. The difference in presentation levels was chosen due to expected ceiling or flooring effects in one group that would occur if the same level was chosen, based on pilot testing.
The 50% SRT was determined using the OLSA with adaptive level control, using both fixed-noise and fixed-speech procedure at 65 dB SPL. Testing was conducted in an open-set format. A practice run with 20 sentences was performed before starting the main test [4].
During the Freiburg and OLSA speech intelligibility measurements, the ear contralateral to the tested ear was either masked using white noise (masking) or occluded with disposable earplugs (uvex x-fit, average attenuation: 37 dB) in combination with over-ear earmuffs (Optime III, Peltor, average attenuation: 34 dB) (occlusion). Masking noise was delivered at a constant level of 65 dB SPL via an MX 170 insert earphone (Sennheiser, Germany). The order of testing conditions (level control procedure and masking technique) was fully randomized (retrospectively verified to result in balanced exposure of both conditions).
Each participant completed all four test configurations, with ears analyzed separately. More precisely, each hearing ear (NH or CI) underwent every experimental condition. The data were pooled across the two adaptive OLSA test conditions for occlusion and masking. Likewise, the data for the fixed-speech and fixed-noise procedure were combined across the two masking conditions.
Psychometric evaluation (participant survey)
After each measurement session, participants completed a questionnaire to indicate their subjective preference regarding the masking method (masking vs. occlusion) and level control procedure (fixed-noise vs. fixed-speech, or no preference in the OLSA).
Statistical analysis
Statistical analyses were performed using RStudio (version 2023.12.1+402) and IBM SPSS Statistics (version 28.0.0.0, build 190). Normal distribution was assessed using the Shapiro–Wilk test. For normally distributed data, paired-sample t-tests were applied. For non-normally distributed data, the Wilcoxon signed-rank test was used. The significance level for all tests was set at p<0.05.
Results
Fixed-speech vs. fixed-noise procedure
Figure 1 [Fig. 1] shows boxplots and individual SRTs measured with the OLSA for both level control procedures on SRTs. The data for NH listeners (left) contains SRTs for both, left and right ear and for both occlusion and masking, resulting in n=60 data points per boxplot. NH data using the fixed-speech procedure showed an interquartile range (IQR) from –6.5 dB SNR to –4.8 dB SNR, while for fixed-noise, it ranged from –6.5 dB SNR to –4.9 dB SNR. The median SNR was –5.8 dB for fixed-speech and –5.7 dB for fixed-noise. Mean values were –5.8 dB SNR (fixed-speech) and –5.7 dB SNR (fixed-noise). Statistical analysis revealed no significant differences between procedures (p=0.37, t-test). Data of same ears are connected in Figure 1 [Fig. 1] with dashed lines to allow observation of individual changes across conditions. Considering the test-retest standard deviation of 0.6 dB for the OLSA in NH listeners [12] and assuming normal distribution of SRT-differences (with 95%-confidence intervals of ±1.2 dB), 45 out of the 60 data pairs fall within test-retest 95%-confidence limits. Out of the remaining 15 data pairs that exceed test-retest limits, 9 data pairs show significantly lower (i.e., better) SRTs for fixed-speech and 6 data pairs show significantly lower SRTs for fixed-noise.
Figure 1: Box plots of SRTs (median ± IQR) for the fixed-speech and fixed-noise procedures in NH listeners (left) and CI users (right). Statistical analysis revealed no significant differences between procedures within each participant group (NH: p=0.37, t-test, CI: p=0.70, Wilcoxon test).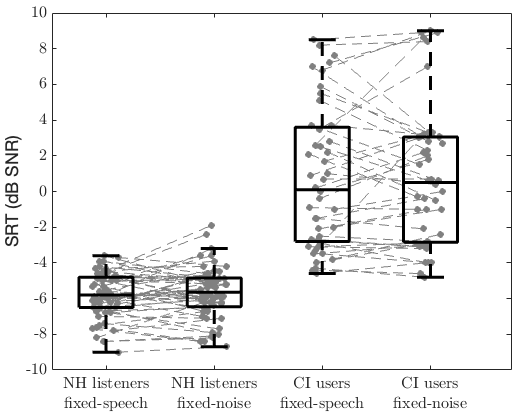
The data for CI users (right) contains SRTs of all 26 CI users, in particular: 5 SRTs from the CI users with contralateral deafness, 6 SRTs from 3 bilaterally implanted CI users being measured on both sides separately, 3 SRTs from 3 bilaterally implanted CI users being measured on one side only, and 30 SRTs measured on the CI side of those 15 CI users with NH contralaterally (once with contralateral hearing occluded and once masked) pooled to n=44 SRTs. CI users’ SRTs showed IQR of –2.8 dB SNR to 3.6 dB SNR using the fixed-speech procedure, while for fixed-noise IQRs ranged from –2.9 dB SNR to 3.1 dB SNR. The median SNR was 0.1 dB for fixed-speech and 0.5 dB for fixed-noise. Mean SNRs were 0.7 dB (fixed-speech) and 0.8 dB (fixed-noise). Statistical analysis revealed no significant differences between procedures (p=0.70, Wilcoxon test). Considering the test-retest standard deviation of 1.1 dB for the OLSA in CI users [6] and assuming normal distribution of SRT-differences (with 95%-confidence intervals of ±2.2 dB), 35 out of the 44 data pairs fall within test-retest 95%-confidence limits. Out of the remaining 9 data pairs that exceed test-retest limits, 3 data pairs show significantly lower (i.e., better) SRTs for fixed-speech and 6 data pairs show significantly lower SRTs for fixed-noise.
Masking vs. occlusion method
Boxplots and individual speech intelligibility scores measured using the Freiburg Monosyllabic Word Test for the masking and occlusion conditions are presented in Figure 2 [Fig. 2]. The data of NH listeners (left) contains speech intelligibility scores for both, left and right ear, resulting in n=30 scores. For the masking condition in NH listeners, the interquartile range (IQR) was 85% to 100%, with a median of 90%. In the occlusion condition, the IQR ranged from 85% to 100% as well, with a higher median of 95%. Mean scores were 87% for masking and 89% for occlusion. Statistical analysis revealed no significant differences between conditions (p=0.12, Wilcoxon test). Individual analysis of speech intelligibility scores considering test-retest reliability using Poisson binomial distribution [33] revealed that all 30 data pairs were within 95%-confidence limits. The data for CI users contains n=14 speech intelligibility scores per condition, only for those CI users with contralateral normal hearing. Note that one data pair of one CI user with contralateral NH is missing due to measurement error. The results for CI users showed an IQR for the masking condition from 45% to 75%, with a median of 65%, while for occlusion, it ranged from 49% to 71%, with a median of 63%. Mean scores were 61% (masking) and 59% (occlusion). Statistical analysis revealed no significant differences between conditions (p=0.33, t-test). Also here all data pairs were within test-retest 95%-confidence limits.
Figure 2: Box plots of Freiburg speech intelligibility scores for masking and occlusion conditions (median ± IQR) in NH listeners (left) and CI users (right). Statistical analysis revealed no significant differences between conditions within each participant group (NH: p=0.12, Wilcoxon test, CI: p=0.33, t-test).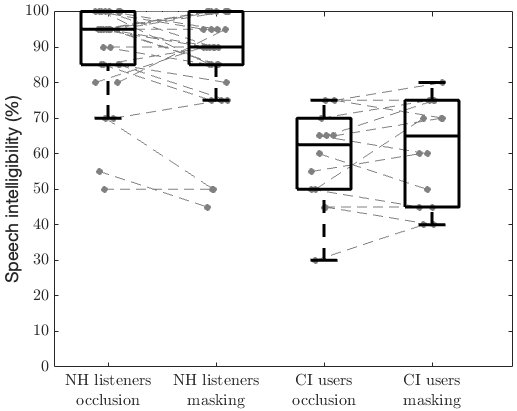
Figure 3 [Fig. 3] shows box plots and individual SRTs measured using the OLSA for both masking and occlusion conditions. The data pooling and thus the number of SRTs for NH listeners is the same as in Figure 1 [Fig. 1], i.e., n=60 per condition. For the NH group, the IQR in the occlusion condition, the IQR was –6.3 dB SNR to –4.8 dB SNR, and the median was –5.4 dB SNR. In the masking condition the IQR ranged from –6.7 dB SNR to –4.9 dB SNR, with a median of –5.9 dB SNR. Mean values were –5.6 dB SNR (occlusion) and –5.9 dB SNR (masking). Statistical analysis showed that SRTs in the masking condition are significantly lower than in the occlusion condition (p=0.014, t-test). Individual analysis of differences across the two conditions revealed that 6 out of the 60 data pairs were exceeding the test-retest 95%-confidence limits of ±1.2 dB, of which 5 were showing significantly lower (i.e., better) SRTs for masking and only 1 showing a lower SRT for occlusion.
Figure 3: Box plots of speech reception thresholds (SRTs, median ± IQR) for contralateral masking and occlusion in NH listeners (left) and CI users (right). Statistical analysis showed significantly lower SRTs for masking in NH listeners, and no significant differences between conditions within each participant group (NH: p=0.014, t-test, CI: p=0.90, Wilcoxon test).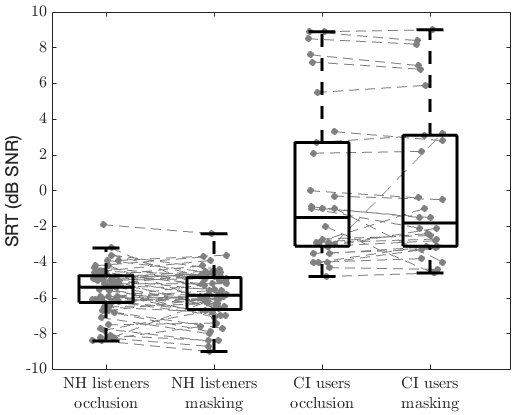
The data for CI users contains 15 SRTs per condition, because it was possible to occlude or mask the contralateral side only for those CI patients with contralateral normal hearing. In these CI patients, the IQR for masking was –3.1 dB SNR to 3.1 dB SNR, while for occlusion it was –3.2 dB SNR to 2.9 dB SNR. Mean SNRs were 0.1 dB (masking) and 0.0 dB (occlusion). Statistical analysis showed no significant differences between groups (p=0.90, Wilcoxon test). Out of the 15 data pairs, 2 were exceeding the test-retest 95%-confidence limits of ±2.2 dB, both showing significantly lower SRTs with masking than with occlusion.
Subjective preference ratings
Figure 4 [Fig. 4] shows subjective preference ratings from NH listeners (left) and CI users (right) about the level control procedure. Forty percent of NH listeners reported no clear preference between fixed speech and fixed noise procedure. Another 40% preferred fixed speech procedure, whereas 20% preferred the fixed noise condition. Fifty percent of CI users rated the fixed noise procedure as more comfortable compared to 31% for fixed speech. Nineteen percent did not report a clear preference.
Figure 4: Distribution of subjectively preferred level control procedures (fixed-speech vs. fixed-noise) in NH listeners (left) and CI users (right)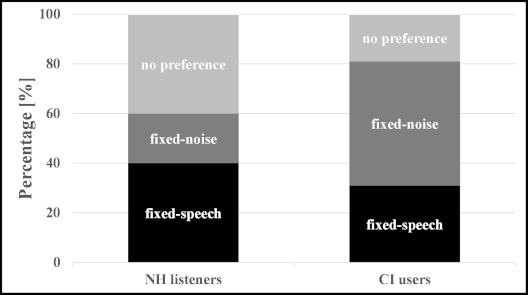
Figure 5 [Fig. 5] shows subjective preference ratings from NH listeners (left) and CI users (right) about the occlusion vs. masking conditions. 69% of NH listeners preferred the occlusion condition, while only 31% rated the masking condition as more comfortable. Subjective ratings in CI users indicated that 73% preferred the occlusion condition, while only 18% favored masking. Nine percent did not express a preference). In summary this indicates a clear preference for occlusion of the non-tested ear over masking in both participant groups.
Figure 5: Distribution of subjectively preferred conditions (masking vs. occlusion) in NH listeners (left) and CI users (right)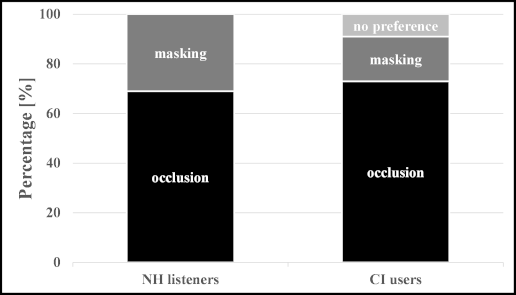
Discussion
The present study found no significant differences between using fixed-speech or fixed-noise procedures in adaptive speech-in-noise testing with NH listeners and CI users on the group level. There were also no significant differences between speech intelligibility scores (or SRTs) measured by occluding the contralateral ear in comparison to masking the contralateral ear with noise presented using in-ear headphones on the group level in CI users. In NH listeners, SRTs with masking were significantly lower than with occlusion. Despite lack of significant differences, there was a clear preference for the fixed-noise procedure expressed by CI users, and a clear preference for the fixed-speech procedure by NH listeners. In addition, in both patient groups there was a clear preference for using occlusion with earplugs and over-ear earmuffs in comparison to masking for blocking the contralateral ear.
No significant differences between fixed-speech or fixed-noise procedures using the OLSA were also found by Wagener and Brand [13] for NH listeners using headphone presentation and by Dziemba and colleagues [12] for CI users using loudspeaker presentation. The present study therefore reproduces these findings, but also completes them, because here both participant groups were tested using the exact same loudspeaker presentation setup. The fact that no differences occur between SRTs measured using these two procedures can most likely be traced back to both participant groups consisting of sufficient input dynamic range for both procedures. With sufficient input dynamic range, the fixed signal (either speech or noise) is well audible to each participant throughout the entire measurement run and level changes of the adapted signal (noise or speech) lead to the same threshold. This could be different for listeners with very limited input dynamic range such as persons with severe sensorineural hearing impairment. For them, a fixed-noise procedure could virtually be an adaptive speech intelligibility measurement in quiet, because the noise may be below their (strongly elevated) hearing threshold [34] resulting in substantially raised SRTs. Wagener and Brand [13] tested fixed-noise vs. fixed-speech procedures with the OLSA in moderately hearing-impaired listeners. However, a small number of subjects and their less severe hearing impairment did not allow for strong conclusions. A direct comparison of fixed-noise and fixed-speech procedures in severely hearing-impaired listeners is therefore still missing in the literature. There were, however, substantially more individual SRT-differences between fixed-noise and fixed speech conditions out of test-retest confidence limits than expected from the literature. The fact that these were non-systematic (i.e., not all showing lower SRT in one specific condition) indicates that test-retest reliability for the OLSA in the participants of the present study may be slightly larger than reported by [6] and [13], possibly due to a more diverse patient recruitment here (larger age range in NH listeners and larger performance range in CI users).
Subjectively, CI users preferred the fixed-noise procedure over the fixed-speech procedure, whereas NH listeners preferred the fixed-speech procedure. Clinically, both procedures could be used if there is no methodological reason to choose either fixed-noise or fixed-speech procedure. However, it is important to ensure that SNR values do not exceed 5 dB to avoid sum level effects during stimulus presentation as well as insufficient contralateral masking [12].
The direct comparison of occlusion vs. masking the contralateral ear in the same participant groups is novel and has not been reported before. The present study shows that for the group of CI users both methods (occlusion and masking) produce the same results for the target ear. This indicates that also comparisons between studies choosing occlusion [12], [25], [29] and masking [2], [18], [30] methods to exclude the contralateral ear are allowed. In turn, our study removes caveats being expressed in these studies with respect to comparisons due to different occlusion or masking methods.
Psychoacoustically, masking the contralateral ear with noise leads to a more symmetric percept during the measurement, because signals on both ears are perceived as similarly loud. In contrast, occluding the ear canal with ear plugs and ear muffs leads to strongly asymmetric loudness perception. As stated in the introduction, the symmetric loudness perception hypothesis (masking condition favored due to similar loudness perception across ears) seems reasonable given that unilateral stimulation leads to higher subjectively perceived listening effort [31]. On the other hand, also the distraction hypothesis (masking with noise may be perceived as more distracting from the target signal presented on the opposite ear in comparison to the quiet present in the occlusion condition) seems reasonable. The present study shows a clear preference in most participants for occluding the contralateral ear, especially in the CI users. This highlights that in most patients the distraction hypothesis holds more likely than the symmetric loudness perception hypothesis. Individual data did not indicate any relationship between subjective preference and speech understanding in different testing conditions.
In order to make the measurements most pleasurable for the patients, therefore, the present study recommends to occlude the contralateral ear rather than to mask it with noise. However, this recommendation needs to be taken with care, because occlusion will only attenuate the loudspeaker signal via airborne sound transmission by the total attenuation delivered by the combination of ear plug and ear muffs. Despite this substantial attenuation, two factors may result in the (attenuated) loudspeaker signal still reaching the contralateral inner ear: An individual poor fit of ear plugs or ear muffs, and the direct air-to-bone conduction bypassing ear plug and ear muffs that results in about 40–60 dB attenuation to the inner ear [35]. Either one or both of these might allow the occluded ear to partly contribute to the speech intelligibility result, at least if the occluded ear consists of normal hearing. The fact that no significant differences in SRTs or speech intelligibility scores on the group level were found in the present study for CI users indicates that non-perfect occlusion does not play a major role in clinical practice. In addition, the small (0.5 dB), but significantly higher (i.e., poorer) SRTs for NH listeners in the occlusion condition show that inadequate occlusion is not an issue for this participant group either, because non-sufficient occlusion and thus contribution of the contralateral ear would have led to lower (and not higher) SRTs in the occlusion condition.
Looking at individual CI users’ SRTs, there were two data pairs (occlusion vs. masking) out of 95% confidence limits (both from the same CI user with contralateral NH). Also here, this CI user’s SRTs measured with occlusion were significantly higher than with masking indicating that unsatisfactory attenuation to the contralateral ear is not a problem in this user. Along the same lines, 5 out of 6 data pairs in NH listeners showed significantly lower SRTs for the masking condition.
In summary, the present study shows that the occlusion used here is as effective in excluding the contralateral ear as masking it with noise, and there is no effect on SRTs, at least in CI users. In addition, unsatisfactory attenuation of the contralateral ear will even play less of a role if the contralateral inner ear would be impaired. Different fits of occlusion or the attenuation limit of air-to-bone conduction were not investigated systematically in the present study, but should be investigated in future studies to refine the clinical recommendation given here. In the condition of masking with white noise, insufficient masking is less likely when using in-ear headphones, because patients will most likely be more aware if they hear the masking noise [34] and will report an insufficient fit of the in-ear headphone than they will report an insufficient fit of the occlusion.
Conclusions
No significant differences were found between SRTs measured using fixed-noise and fixed-speech procedures in adaptive speech-in-noise testing for NH listeners or CI users on the group level. The clear preference for the fixed-noise procedure from CI users allows for a recommendation of the fixed-noise procedure in a clinical context.
Also, speech intelligibility scores and SRTs were not significantly different between masking with white noise and occlusion of the contralateral ear in CI users, despite the physical attenuation limits of occlusion in practice. For NH listeners, SRTs were significantly lower (i.e., better) for masking compared to occlusion. Both NH listeners and CI users clearly preferred occlusion over masking.
Abbreviations
- CI: cochlear implant
- DGHNO-KHC: Deutsche Gesellschaft für Hals-, Nasen-, Ohrenheilkunde, Kopf- und Halschirurgie
- HL: hearing level
- IQR: interquartile range
- NH: normal-hearing
- OLSA: Oldenburg sentence test
- SNR: signal-to-noise ratio
- SPL: sound pressure level
- SRT: speech reception threshold
Notes
Competing interests
The authors declare that they have no competing interests.
References
[1] Gifford RH, Driscoll CL, Davis TJ, Fiebig P, Micco A, Dorman MF. A Within-Subject Comparison of Bimodal Hearing, Bilateral Cochlear Implantation, and Bilateral Cochlear Implantation With Bilateral Hearing Preservation: High-Performing Patients. Otol Neurotol. 2015 Sep;36(8):1331-7. DOI: 10.1097/MAO.0000000000000804[2] Hoppe U, Hocke T, Digeser F. Bimodal benefit for cochlear implant listeners with different grades of hearing loss in the opposite ear. Acta Otolaryngol. 2018 Aug;138(8):713-21. DOI: 10.1080/00016489.2018.1444281
[3] Kollmeier B, Warzybok A, Hochmuth S, Zokoll MA, Uslar V, Brand T, Wagener KC. The multilingual matrix test: Principles, applications, and comparison across languages: A review. Int J Audiol. 2015;54 Suppl 2:3-16. DOI: 10.3109/14992027.2015.1020971
[4] Wagener K, Kühnel V, Kollmeier B. Entwicklung und Evaluation eines Satztests für die deutsche Sprache I: Design des Oldenburger Satztests. Zeitschrift für Audiologie/Audiological Acoustics. 1999;38:4-15.
[5] Mrowinski D, Scholz G, Steffens T. Audiometrie: Eine Anleitung für die praktische Hörprüfung. Stuttgart: Thieme; 2022.
[6] Hey M, Hocke T, Hedderich J, Müller-Deile J. Investigation of a matrix sentence test in noise: reproducibility and discrimination function in cochlear implant patients. Int J Audiol. 2014 Dec;53(12):895-902. DOI: 10.3109/14992027.2014.938368
[7] Gifford RH, Dorman MF, Shallop JK, Sydlowski SA. Evidence for the expansion of adult cochlear implant candidacy. Ear Hear. 2010 Apr;31(2):186-94. DOI: 10.1097/AUD.0b013e3181c6b831
[8] Croghan NBH, Smith ZM. Speech Understanding With Various Maskers in Cochlear-Implant and Simulated Cochlear-Implant Hearing: Effects of Spectral Resolution and Implications for Masking Release. Trends Hear. 2018 Jan-Dec;22:2331216518787276. DOI: 10.1177/2331216518787276
[9] Steffens T. Die systematische Auswahl von sprachaudiometrischen Verfahren [The systematic selection of speech audiometric procedures]. HNO. 2017 Mar;65(3):219-27. DOI: 10.1007/s00106-016-0249-0
[10] Williges B, Wesarg T, Jung L, Geven LI, Radeloff A, Jürgens T. Spatial Speech-in-Noise Performance in Bimodal and Single-Sided Deaf Cochlear Implant Users. Trends Hear. 2019 Jan-Dec;23:2331216519858311. DOI: 10.1177/2331216519858311
[11] Zedan A, Jürgens T, Williges B, Kollmeier B, Wiebe K, Galindo J, Wesarg T. Speech Intelligibility and Spatial Release From Masking Improvements Using Spatial Noise Reduction Algorithms in Bimodal Cochlear Implant Users. Trends Hear. 2021 Jan-Dec;25:23312165211005931. DOI: 10.1177/23312165211005931
[12] Dziemba OC, Oberhoffner T, Müller A. OLSA-Pegelsteuerung bei monauraler Sprachaudiometrie im Störschall zur Evaluation des CI-Versorgungsergebnisses [OLSA level control in monaural speech audiometry in background noise for the evaluation of the CI fitting result]. HNO. 2023 Feb;71(2):100-5. DOI: 10.1007/s00106-022-01251-0
[13] Wagener KC, Brand T. Sentence intelligibility in noise for listeners with normal hearing and hearing impairment: influence of measurement procedure and masking parameters. Int J Audiol. 2005 Mar;44(3):144-56. DOI: 10.1080/14992020500057517
[14] Arndt S, Aschendorff A, Laszig R, Beck R, Schild C, Kroeger S, Ihorst G, Wesarg T. Comparison of pseudobinaural hearing to real binaural hearing rehabilitation after cochlear implantation in patients with unilateral deafness and tinnitus. Otol Neurotol. 2011 Jan;32(1):39-47. DOI: 10.1097/MAO.0b013e3181fcf271
[15] Deutsche Gesellschaft für Hals-Nasen-Ohrenheilkunde, Kopf- und Hals-Chirurgie. Weißbuch Cochlea-Implantat(CI)-Versorgung. 2nd ed. Bonn: 2021.
[16] Lehnhardt E, Laszig R. Praxis der Audiometrie. Stuttgart: Thieme; 2001.
[17] Culling JF, Jelfs S, Talbert A, Grange JA, Backhouse SS. The benefit of bilateral versus unilateral cochlear implantation to speech intelligibility in noise. Ear Hear. 2012 Nov-Dec;33(6):673-82. DOI: 10.1097/AUD.0b013e3182587356
[18] Hey M, Kogel K, Dambon J, Mewes A, Jürgens T, Hocke T. Factors to Describe the Outcome Characteristics of a CI Recipient. J Clin Med. 2024 Jul 29;13(15):4436. DOI: 10.3390/jcm13154436
[19] Jürgens T, Hohmann V, Büchner A, Nogueira W. The effects of electrical field spatial spread and some cognitive factors on speech-in-noise performance of individual cochlear implant users-A computer model study. PLoS One. 2018 Apr 13;13(4):e0193842. DOI: 10.1371/journal.pone.0193842
[20] Eskridge EN, Galvin JJ 3rd, Aronoff JM, Li T, Fu QJ. Speech perception with music maskers by cochlear implant users and normal-hearing listeners. J Speech Lang Hear Res. 2012 Jun;55(3):800-10. DOI: 10.1044/1092-4388(2011/11-0124)
[21] Stronks HC, Apperloo E, Koning R, Briaire JJ, Frijns JHM. SoftVoice Improves Speech Recognition and Reduces Listening Effort in Cochlear Implant Users. Ear Hear. 2021 Mar/Apr;42(2):381-92. DOI: 10.1097/AUD.0000000000000928
[22] Baumgärtel RM, Hu H, Krawczyk-Becker M, Marquardt D, Herzke T, Coleman G, Adiloğlu K, Bomke K, Plotz K, Gerkmann T, Doclo S, Kollmeier B, Hohmann V, Dietz M. Comparing Binaural Pre-processing Strategies II: Speech Intelligibility of Bilateral Cochlear Implant Users. Trends Hear. 2015 Dec 30;19:2331216515617917. DOI: 10.1177/2331216515617917
[23] Kan A. Improving Speech Recognition in Bilateral Cochlear Implant Users by Listening With the Better Ear. Trends Hear. 2018 Jan-Dec;22:2331216518772963. DOI: 10.1177/2331216518772963
[24] Xie Z, Gaskins CR, Shader MJ, Gordon-Salant S, Anderson S, Goupell MJ. Age-Related Temporal Processing Deficits in Word Segments in Adult Cochlear-Implant Users. Trends Hear. 2019 Jan-Dec;23:2331216519886688. DOI: 10.1177/2331216519886688
[25] Zhou X, Innes-Brown H, McKay CM. Audio-visual integration in cochlear implant listeners and the effect of age difference. J Acoust Soc Am. 2019 Dec;146(6):4144. DOI: 10.1121/1.5134783
[26] Bernstein JG, Goupell MJ, Schuchman GI, Rivera AL, Brungart DS. Having Two Ears Facilitates the Perceptual Separation of Concurrent Talkers for Bilateral and Single-Sided Deaf Cochlear Implantees. Ear Hear. 2016 May-Jun;37(3):289-302. DOI: 10.1097/AUD.0000000000000284
[27] Williges B, Jürgens T, Hu H, Dietz M. Coherent Coding of Enhanced Interaural Cues Improves Sound Localization in Noise With Bilateral Cochlear Implants. Trends Hear. 2018 Jan-Dec;22:2331216518781746. DOI: 10.1177/2331216518781746
[28] Grange JA, Culling JF. Head orientation benefit to speech intelligibility in noise for cochlear implant users and in realistic listening conditions. J Acoust Soc Am. 2016 Dec;140(6):4061. DOI: 10.1121/1.4968515
[29] El Boghdady N, Langner F, Gaudrain E, Başkent D, Nogueira W. Effect of Spectral Contrast Enhancement on Speech-on-Speech Intelligibility and Voice Cue Sensitivity in Cochlear Implant Users. Ear Hear. 2021 Mar/Apr;42(2):271-89. DOI: 10.1097/AUD.0000000000000936
[30] Murr AT, Canfarotta MW, O'Connell BP, Buss E, King ER, Bucker AL, Dillon SA, Rooth MA, Dedmon MM, Brown KD, Dillon MT. Speech Recognition as a Function of Age and Listening Experience in Adult Cochlear Implant Users. Laryngoscope. 2021 Sep;131(9):2106-11. DOI: 10.1002/lary.29663
[31] Hollfelder D, Prein L, Leichtle A, Bruchhage KL, Jürgens T. Middle Ear Implant Usage Restores Subjective Listening Effort toward Normal in Complex Acoustic Scenes. Audiol Neurootol. 2023;28(3):211-8. DOI: 10.1159/000528025
[32] Hoth S, Rösli-Khabas M, Herisanu I, Plinkert PK, Praetorius M. Cochlear implantation in recipients with single-sided deafness: Audiological performance. Cochlear Implants Int. 2016 Jul;17(4):190-9. DOI: 10.1080/14670100.2016.1176778
[33] Holube I, Winkler A, Nolte-Holube R. Modellierung und Verifizierung der Test-Retest-Reliabilität des Freiburger Einsilbertests in Ruhe mit der verallgemeinerten Binomialverteilung. GMS Z Audiol (Audiol Acoust). 2020;2:Doc03. DOI: 10.3205/zaud000007
[34] Wardenga N, Batsoulis C, Wagener KC, Brand T, Lenarz T, Maier H. Do you hear the noise? The German matrix sentence test with a fixed noise level in subjects with normal hearing and hearing impairment. Int J Audiol. 2015;54 Suppl 2:71-9. DOI: 10.3109/14992027.2015.1079929
[35] Zwislocki JJ, Rosowski JJ. Auditory Sound Transmission: An Autobiographical Perspective. The Journal of the Acoustical Society of America. 2003;113(3):1191.

